Deep Reinforcement Learning for Urban Modeling: Morphogenesis Simulation of Self Organized Settlements
Master's Thesis: Houssame Eddine H’sain(Bilkent University, 2023)
Advisors: Burcu Şenyapılı Özcan, Yiğit Acar (Co-Advisor)
This study investigates the potential of self-organized modes of urban growth to produce high-quality urban spaces, emphasizing their capacity to offer affordable housing and broaden access to economic opportunities. Capturing the non-linear, dynamic, and complex nature of this sequential urban aggregation process demands adaptive, data-driven decision-making.
To address this challenge, a deep reinforcement learning (DRL) approach is proposed to autonomously learn adaptive decision policies for generating self-organized settlements optimized for specific performance objectives. A conceptual framework is introduced to model the morphogenesis of such settlements within a single-agent reinforcement learning (RL) environment.
This framework is validated through the development of three experimental environments derived from two cellular automata-based urban growth models. Within these environments, RL agents are trained using Deep Q-learning (DQN) and Proximal Policy Optimization (PPO) algorithms to learn policies for sequential urban aggregation that optimize performance metrics.
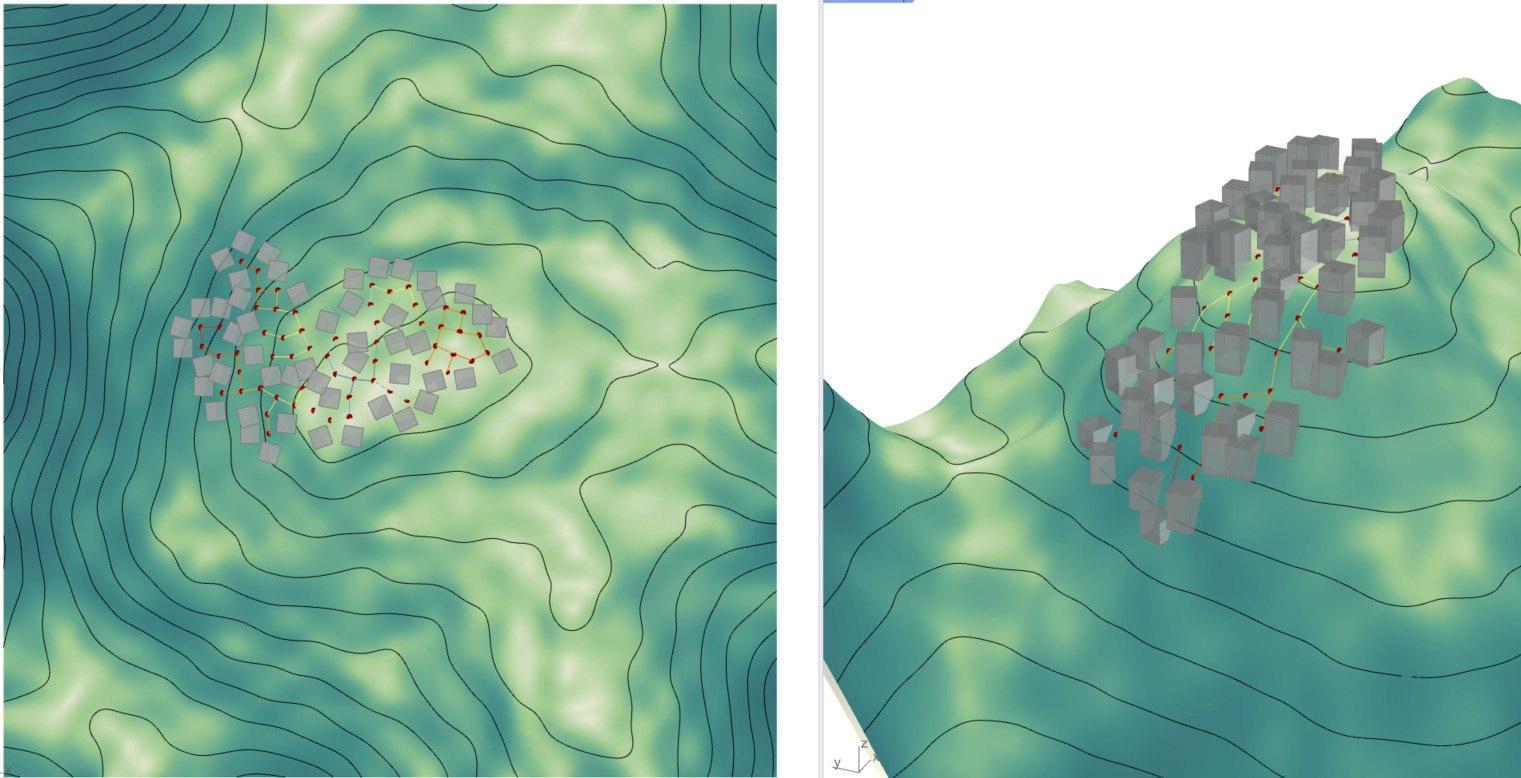
The trained agents demonstrate the ability to incrementally grow settlements while dynamically adapting their morphology to satisfy performance goals, preserve right-of-way, and respond to topographic conditions. Beyond modeling self-organized settlement growth, the proposed method presents a generalizable strategy for addressing a broader range of generative design problems formulated as single-agent sequential decision-making tasks.

*An earlier version of the training results using PPO algorithm with a simple MLP policy network on the local observation version of the Beady Ring environment. Observation: 1*9 vector representing the Moore neighborhood of the action cell. Reward: +1/total cell count for each house cell event. Grey-empty cell | Black-house cell | White-street cell.

*The very early stages of the work, experimenting with built form generation in urban environments.

Renders of the terminal states of the training episodes of the GPN environment with different topographic constraints (introvert, linear, and extrovert) using PPO.